Support vector machine, SVM (支援向量機演算法)
2021/09/09
SVM也是一個很常見的演算法,網誌的統計篇也越來越充實了,而且目前最廣泛使用的SVM演算法是臺大林智仁教授開發的libsvm,對應到R套件就是e1071,這方面的資源非常非常的多,這裡簡單整理我的自學筆記。
可以參考R筆記、e1071的套件說明等。
何謂SVM
SVM是一種監督式學習 (supervised learning) 演算法,最早由Cortes and Vapnik (1995) 提出,現在引用數也接近五萬次,是一種二元分類器 (binary classifier)。其實SVM的想法早在Vapnik仍在莫斯科大學讀博士班的1960年代就被提出了,可是他沒有合適的電腦來實現這個想法,直到後來Vapnik移民到美國後,大約在這個想法提出三十年後,kernel function也被重視,SVM才開始得到大家的目光,而現今SVM已經是每個要接觸機器學習的人必須了解的東西了。
所謂二元分類器的概念是非常簡單的,如果要用線性的方法區分兩種不同標籤的資料,即用一條直線把兩種標籤的資料區分出來,可以表示如圖1這樣:
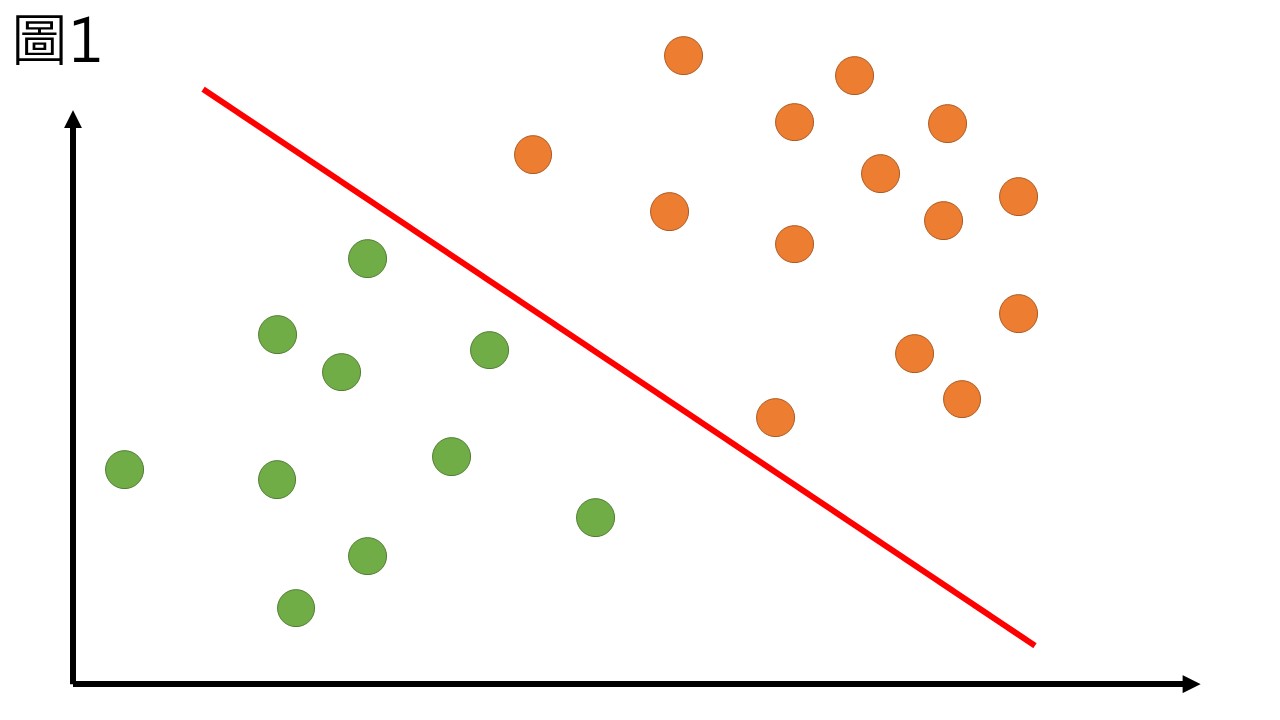
當資料越來越複雜,要用線性的方法區分兩組資料就越來越困難,有時根本沒辦法區分,如圖2(a),以直線根本分不出來吧。
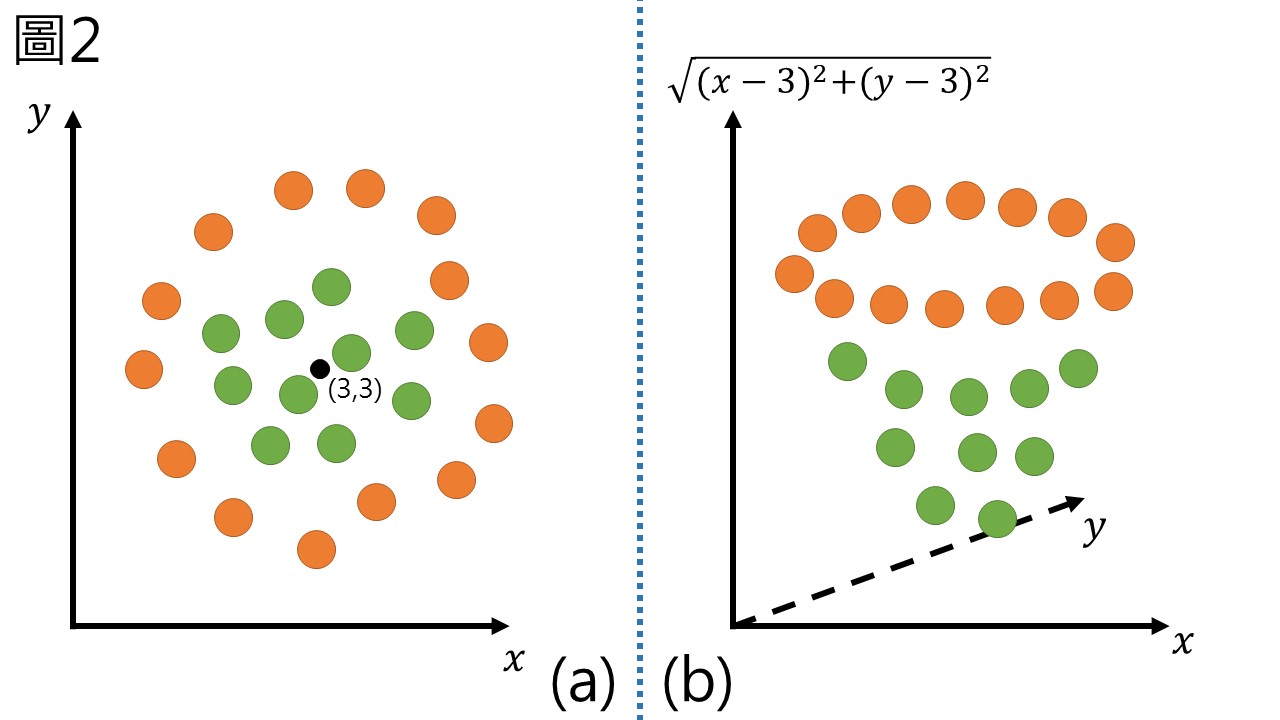
如果兩個維度分不出來,那就用三個吧!把資料映射到一個更高維的空間中,可以讓其更為有效地被區分,讓我們回想高中數學的點距離方程式,在圖2(a) 的中間給定一個點 (3,3),並計算其他點到點 (3,3) 的距離\(\sqrt{(x-3)^2+(y-3)^2}\),並把\(\sqrt{(x-3)^2+(y-3)^2}\)作為圖2(a) 的第三維Z座標繪圖,可以得到圖2(b) 的結果。離 (3,3) 較近的綠色點就會有比較小的Z座標,反之橘色點的Z座標比較大,在圖2(b) 中兩種標籤被很明顯的區隔出來,要用線性的方法區分也很容易,SVM的原理就是以先將資料映射到更高維的空間,再進行二元分類。
當兩種標籤的樣品要被區分出來時,SVM會尋找一個超平面 (hyperplane) 來區隔兩組資料,如圖3。
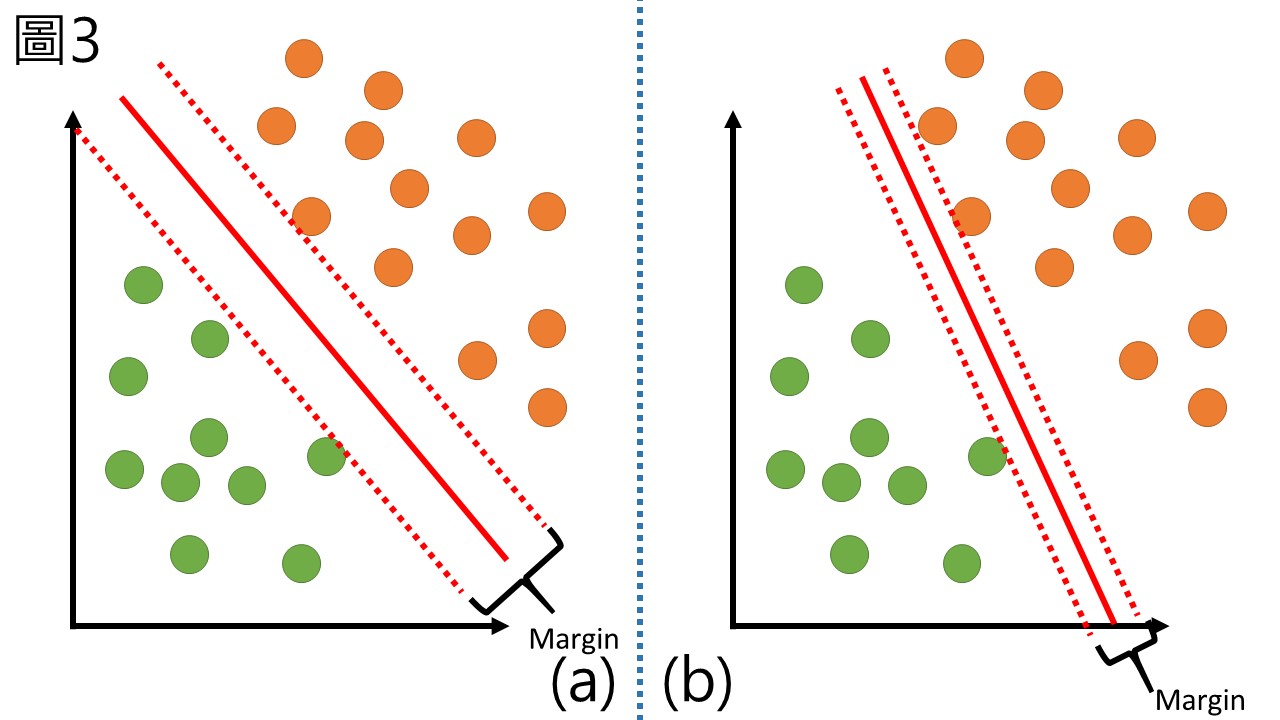
由於超平面是在比原本資料更高維度中,所以在超平面看起來並不一定是直線,但這裡先以直線表示。SVM計算該平面到兩種分類中各自最接近的點的距離,稱作邊界 (margin),平面會與兩邊界保持相同的距離,若邊界越大就代表越能把兩種標籤區分出來,圖3(a) 的邊界就比圖3(b) 來的大,採用圖3(a) 的超平面就更容易區分資料,到這裡差不多是SVM的基本概念,以下介紹更為數學的內容。
尋找超平面
這部分的內容是由MIT的開放式課程內容整理而成。
假設有一個超空間是由\(x_1, x_2, x_3\)三組向量組成,這個空間中的平面可以表示成這樣:
\(\begin{align}
\begin{bmatrix}w_1&w_2&w_3\end{bmatrix}
\begin{bmatrix}x_1\\x_2\\x_3\end{bmatrix} + b &= 0 \\
w^T x + b &= 0 \\
\end{align}\)
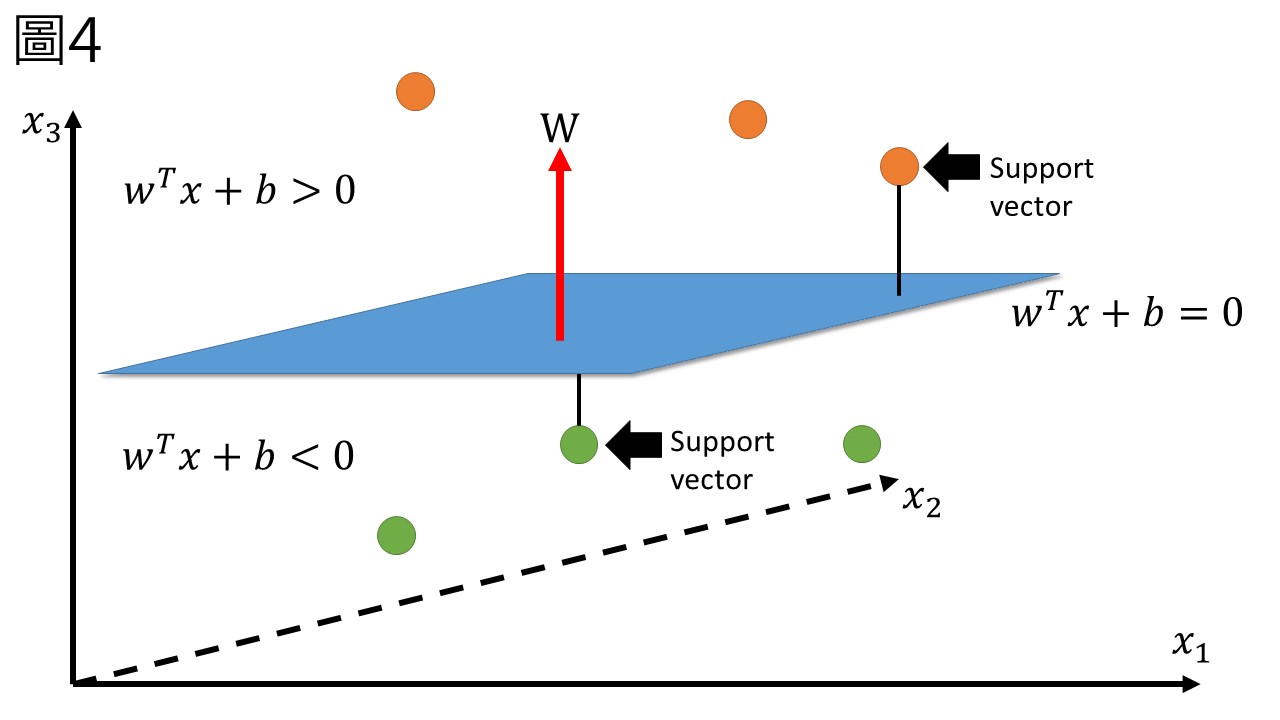
如圖4,\(w\)是與這個平面垂直的向量,他的長短尚未決定,但我們需要找到這個\(w\) (注意:\(w^T x\)就是指w和x向量的內積,我後面沒有明寫但都是代表這樣)。既然分類的超平面是\(w^T x + b = 0\),那麼在平面兩邊的兩組標籤就分別為\(w^T x + b > 0\)及\(w^T x + b < 0\),代入方程式會有不同的正負予以判別。
在圖4中,兩種標籤裡距離平面最近的點稱作support vector (支援向量),support vector們與平面的距離決定了邊界的大小M (圖5),由於\(w\)的長短尚未決定,現在讓我們規定由超平面到兩端最近的點的平面為\(w^T x + b = 1\)和\(w^T x + b = -1\)。
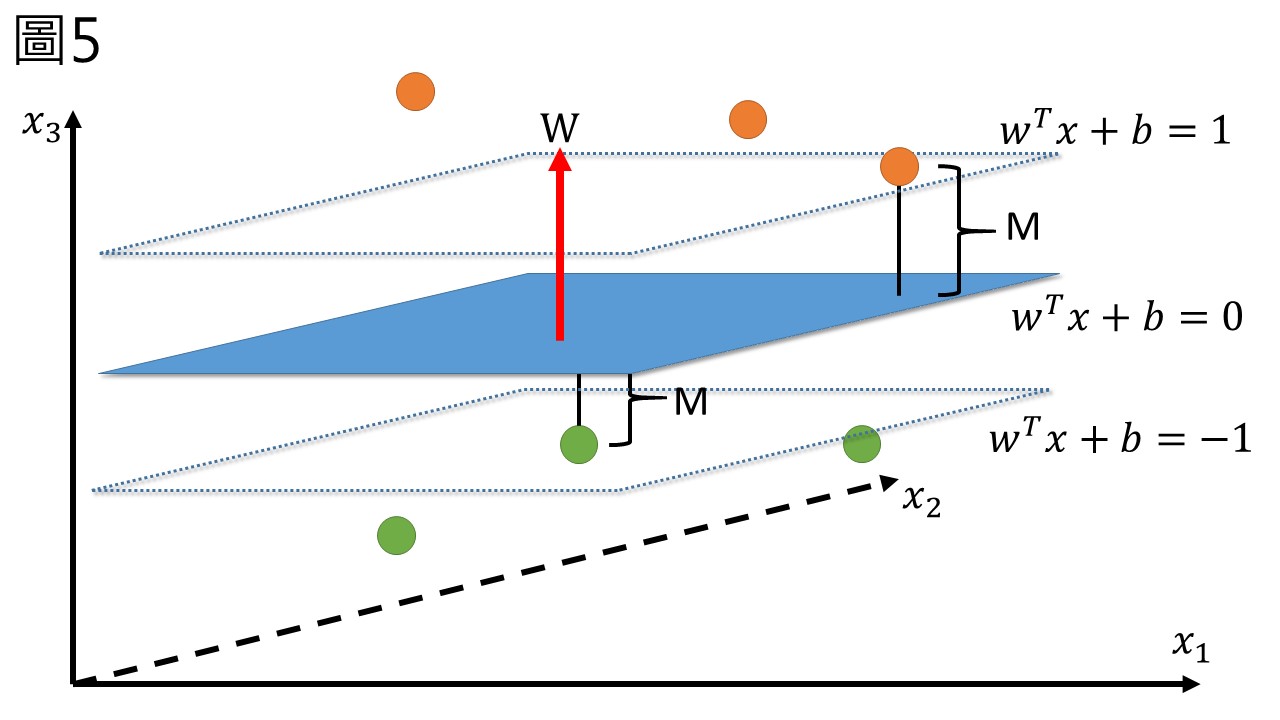
如此一來,我們可以給定圖中的橘色與綠色兩種標籤一個數學上的定義,橘色的標籤在\(w^T x + b = 1\)之上,而綠色在\(w^T x + b = -1\)之下,我們可以說這兩種顏色的標籤會符合:
- 橘色:\(w^T x + b \geq 1\)
- 綠色:\(w^T x + b \leq -1\)
現在給予兩種標籤各自的\(y_i\),橘色為正,綠色為負,即:
- 橘色:\(y_i=+1\)
- 綠色:\(y_i=-1\)
把他們的\(y_i\)代入前面的方程式裡面,神奇的事情就會發生:
- 橘色 (\(y_i=+1\)):\(y_i(w^T x + b) -1 \geq 0\)
- 綠色 (\(y_i=-1\)):\(y_i(w^T x + b) -1 \geq 0\)
哎呀!兩個方程式一樣了,由於綠色乘了一個負數的\(y_i\),所以大小於的符號反過來了,這樣我們可以發現不論是橘色還是綠色,\(y_i(w^T x + b) -1\)都會大於0。
進一步我們要看在平面上的點 (即support vector),可以發現support vector會滿足\(y_i(w^T x + b) -1 = 0\),剛好等於0,我們使用簡單的展開來看
\(y_i(w^T x + b) -1 = 0 \\
y_iw^T x + y_i\ b -1 = 0\\
y_iw^T x = -y_i\ b +1\\
w^T x=\frac{-y_i\ b +1}{y_i}\)
這是我們的魔法方程式,把橘色與綠色的\(y_i\)代入的話會得到:
- 橘色 (+):\(w^T x=1-b\)
- 綠色 (-):\(w^T x=-1-b\)
把這兩個魔法方程式記下來等等會用到。
現在假設在下平面的support vector為\(\overrightarrow{x_0}\),則其滿足\(w^T \overrightarrow{x_0} + b = -1\) (其實w也是向量只是我沒標示),在上平面的support vector為\(\overrightarrow{x_p}\),原理亦同,向量\(\overrightarrow{x_p}-\overrightarrow{x_0}\)連接這兩個support vector (圖6)。
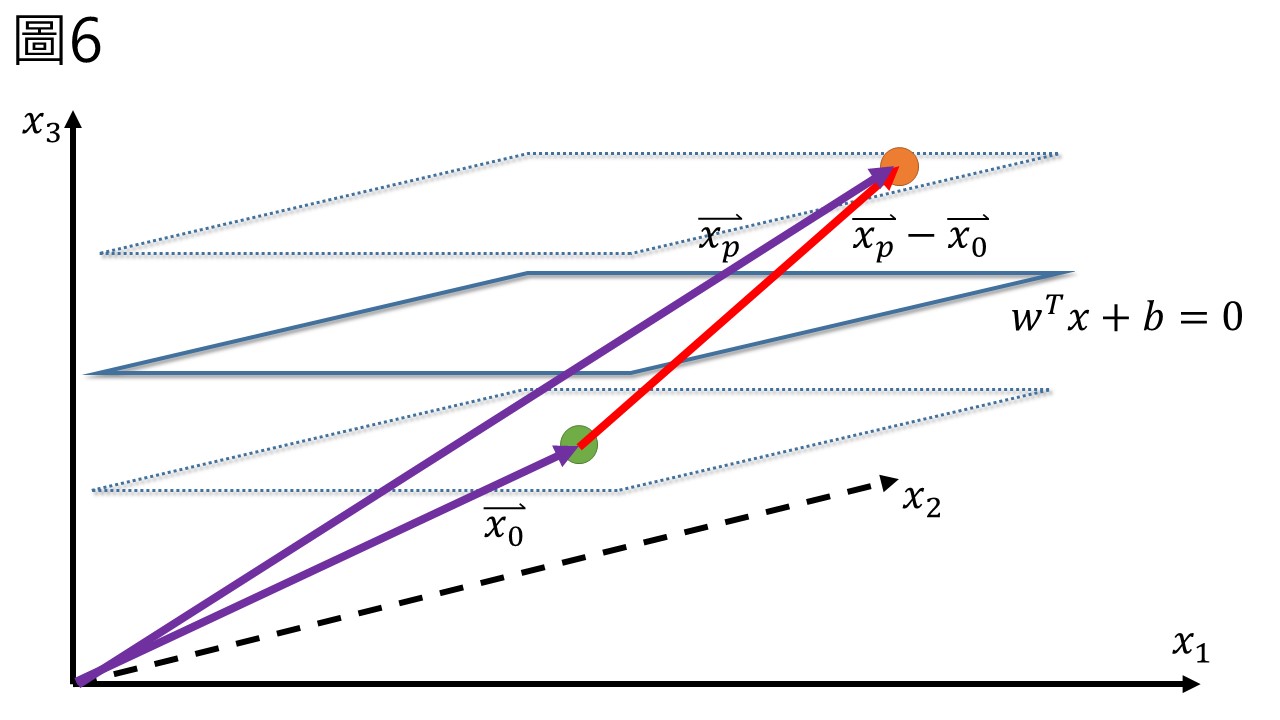
看不清楚的話,從二維圖來看會比較容易 (圖7)。
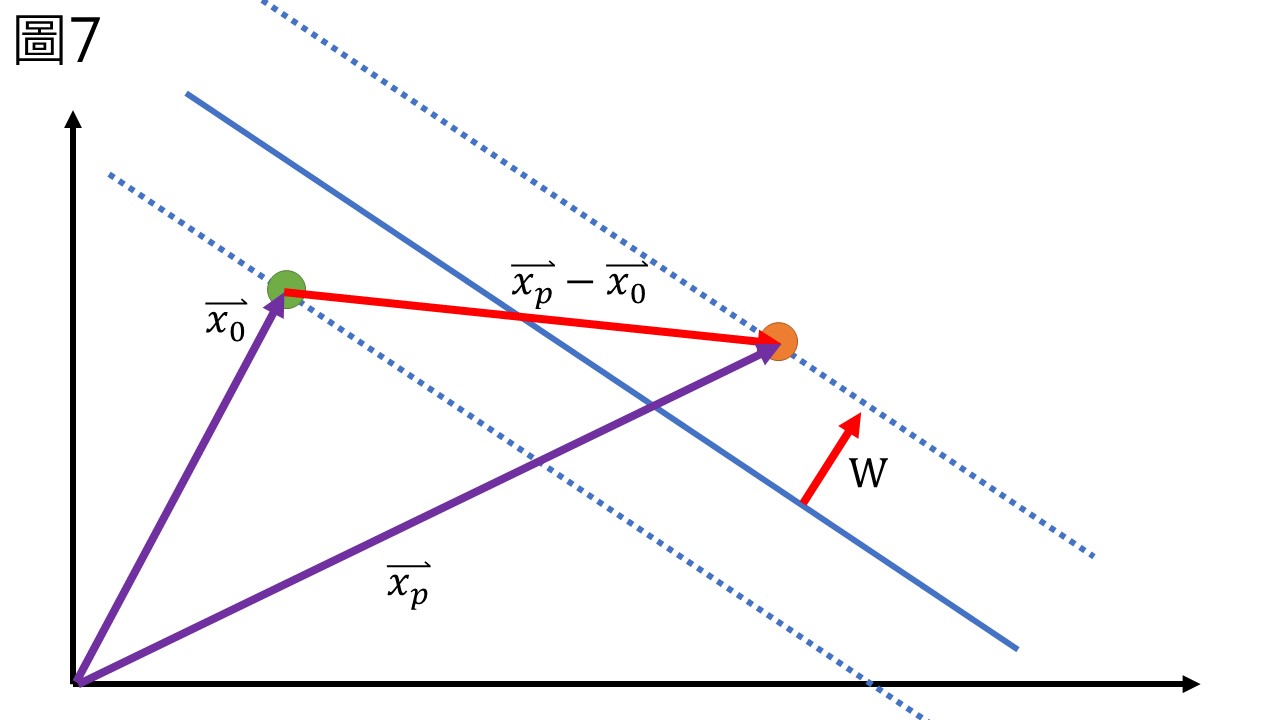
從圖7中我們也不難發現,只要將\(\overrightarrow{x_p}-\overrightarrow{x_0}\)投影到\(w\)上,就可以得到2M的長度,從高中數學裡面我們學到,把一個向量與一個單位向量做內積,就可以得到在單位向量上的投影長度。
接著我們只要使用向量內積搭配上剛剛的魔法方程式就可以做到這樣:
\(\begin{align}
2M &= (\overrightarrow{x_p}-\overrightarrow{x_0}) \cdot \frac{\overrightarrow{w}}{ \begin{Vmatrix}w\end{Vmatrix}}\\
&=\overrightarrow{x_p} \cdot \frac{\overrightarrow{w}}{ \begin{Vmatrix}w\end{Vmatrix}}-\overrightarrow{x_0} \cdot \frac{\overrightarrow{w}}{ \begin{Vmatrix}w\end{Vmatrix}}\\
&=\frac{w^T x_p}{\begin{Vmatrix}w\end{Vmatrix}}-\frac{w^T x_0}{\begin{Vmatrix}w\end{Vmatrix}}\\
&=\frac{1-b}{\begin{Vmatrix}w\end{Vmatrix}}-\frac{-1-b}{\begin{Vmatrix}w\end{Vmatrix}}\\
&=\frac{2}{\begin{Vmatrix}w\end{Vmatrix}}
\end{align}\\\)
因此,要求得最大的M,我們必須求得最大的\(\frac{2}{\begin{Vmatrix}w\end{Vmatrix}}\),也就是求得最小的\(\begin{Vmatrix}w\end{Vmatrix}\)即可。
數學上為了方便,會再將這個問題變成求得最小的\(\frac{1}{2}\begin{Vmatrix}w\end{Vmatrix}^2\),接下來的過程是使用拉格朗日乘子法 (lagrange multiplier),就不在這裡繼續展開。
Kernel
核函數 (kernel function) 是SVM的另一個重點,在圖2中我們見識到了如何讓線性無法區別的資料在另一個維度裡被區別,但要怎麼把資料映射到另外一個維度?這裡的維度不是像PCA的隱藏維度,而是使用kernel function去映射的。
假設我們的資料是\(x\),映射之後的資料為\(\phi(x)\),但找尋適當的映射方程式是較困難的,因此一個較簡單的替代方案是只要尋找映射後的內積即可,因為只要有映射後的內積就可以計算\(w\)了,符合這樣條件的函數稱作kernel function,他的定義是:
\(K(x_i \cdot x_j)=\phi(x_i) \cdot \phi(x_j)\)
使用kernel function就可以獲得映射後的內積,但不用計算映射方程式,因此現在有很多不同種類的kernel function可以利用,包含線性、多項式、Radial Basis Function (RBF) 等,挑選適當的kernel function可以改善SVM的效果。
一樣的,我也會在碩士論文中試用這個分類用的機器學習方法,到時候有什麼新發現會再更新。
參考資料
Cortes, C., Vapnik, V. 1995. Support-vector networks. Machine Learning, 20, 273–297. https://doi.org/10.1007/BF00994018