Cubist regression tree (Cubist迴歸樹)
2021/09/05
Cubist迴歸樹是一個在土壤科學領域 (尤其是數位化土壤繪圖) 相當常見的演算法,是決策樹 (decision tree) 的延伸,這篇文章從決策樹開始講起,最後帶到Cubist迴歸樹。
決策樹模型是出自Ross Quinlan這位澳洲學者,演算法包括ID3、C4.5、C5.0等都被廣泛使用,他創立的公司RuleQuest也將這些方法使用在資料處理上。
Shoot for the moon. Even if you miss, you’ll land among the stars.
—Les Brown
決策樹 (decision tree)
決策樹演算法是監督式學習 (supervised learning) 的一種,監督式學習事先給定資料的標籤,再由演算法進行學習並嘗試預測,白話一點來說,就是教導電腦什麼是鯊魚,什麼是鯨魚,然後再讓電腦看圖辨別魚類,反過來說非監督式學習 (unsupervised learning) 就是未給定資料標籤,讓電腦自己從不同魚類照片中依照形態、大小、顏色等特徵來區分。機器學習的監督式學習通常會輸入一組含有許多變數 (特徵) 的資料,例如我們假設一組動物資料。
| 動物 | 有翅膀 | 會游泳 | 會飛 |
|---|---|---|---|
| 駱駝 | F | F | F |
| 鯊魚 | F | T | F |
| 企鵝 | T | T | F |
| 奇異鳥 | T | F | F |
決策樹的概念相當簡單,以二元區分的方法,一個節點 (node) 代表一項判別,延伸出兩個分支 (符合與否),分支又再到下一個節點,直到區分出所有的資料 (圖1)。
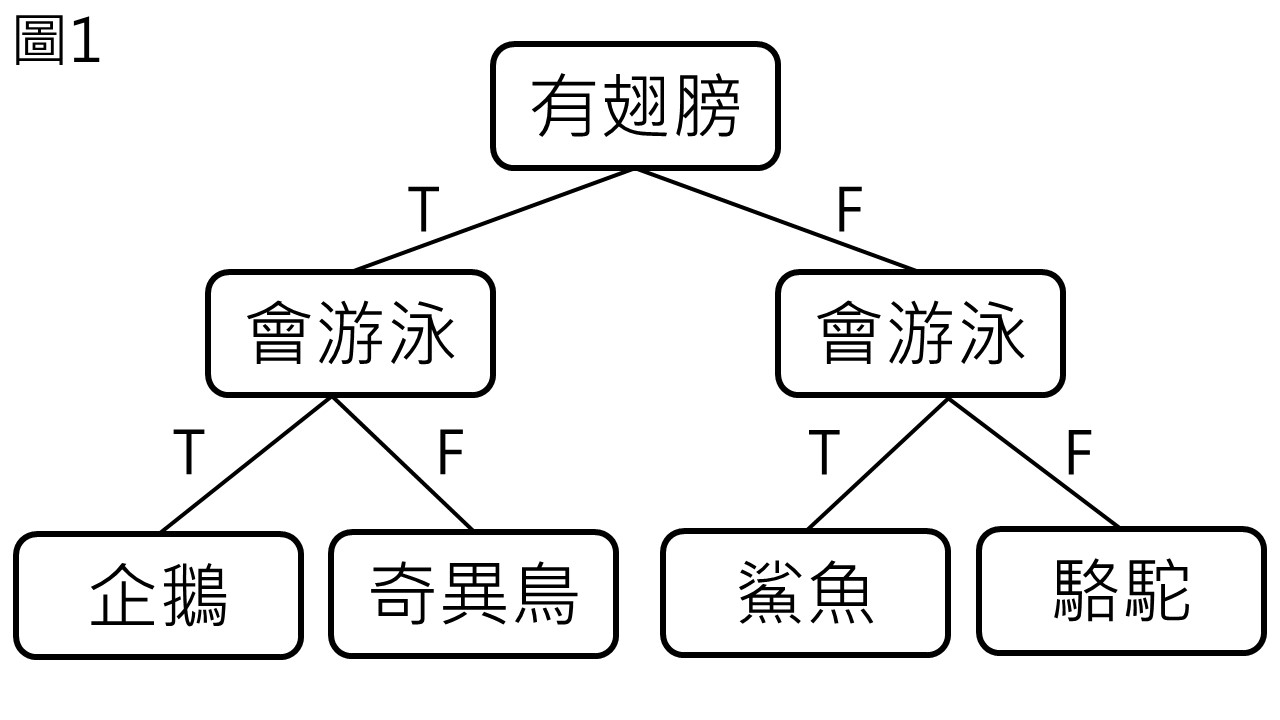
隨之而來的問題是,我們怎麼挑選節點,如圖1中可以看到”會飛”這個項目完全沒有用到,因為四種動物都不會飛,所以不需要用到這個節點,而”有翅膀”和”會游泳”其實都是很能區分動物的節點,而決策樹選擇節點的方法是透過不純度 (impurity)。
一開始的資料是混亂的,這就代表他們的不純度是很高的,假設節點可以將一批不純資料區分成兩批較純的資料,那麼這個節點就是一個好的節點,透過計算分群前和分群後的不純度,決策樹選擇最能降低不純度的節點作為分支。
常見用於代表不純度的方法有兩種,分別為 (1) 熵 (Shannon entropy) 及 (2) 吉尼係數 (Gini index)。
這兩個參數的共通點都是在最混亂時其值最高,當資料越純時數值越小,計算節點所能降低的不純度,就可以找出最好的分群方法,他們的計算方法如下。
在決定好分群方法後,通常會設定一個臨界值,即要分到每一群內的不純度到多小 (因為分到一群只剩一個也沒有意義),滿足條件之後就會停止,以此建構一棵樹,但臨界值的選擇很困難,因此也可以透過事後的修剪 (pruning) 來改善效果,即將有問題的節點移除,這部分就不深入討論。
常見的決策樹種類有很多,包括ID3、C4.5、C5.0與CART (Classificaiton and Regression Trees),這些模型在使用上有一些小差別,但大原則都是遵守前面提到的方法,直到做出一棵樹。
決策樹有其問題,通常是過度適配 (over-fitting) 所導致的,如果臨界值設定的不好也不進行修剪的話,就可能因為某些離群值而造成整個模型過度適配,進而導致實際預測的效果不好,因此決策樹通常不會是機器學習的首選。不過在針對問題進行解決後,許多奠基於決策樹模型的改良演算法,都逐漸成為機器學習的寵兒,例如隨機森林 (random forest)、M5與今天的主角Cubist。
M5迴歸樹 (M5 regression tree)
M5迴歸樹嘗試克服C5.0決策樹中,主要用來預測類別資料 (categorical data) 的這項弱點,可以對連續資料 (continuous data) 進行預測。
當我們要以元素資料預測稻米產量時,決策樹只能告訴你他的產量是”低”、”中”或者”高”,但是迴歸樹卻能直接告訴你4.5這樣的數字,當我們使用多元線性迴歸來預測資料的時候,是將資料建立一條迴歸直線,但我們的資料不必然是遵從同一個規則、同一條迴歸直線,例如圖2的情況,可以很明顯看出分成了 (a)、(b)、(c) 三個區間,(c) 看起來是蠻平的,但是 (a) 跟 (b) 就有趨勢存在。
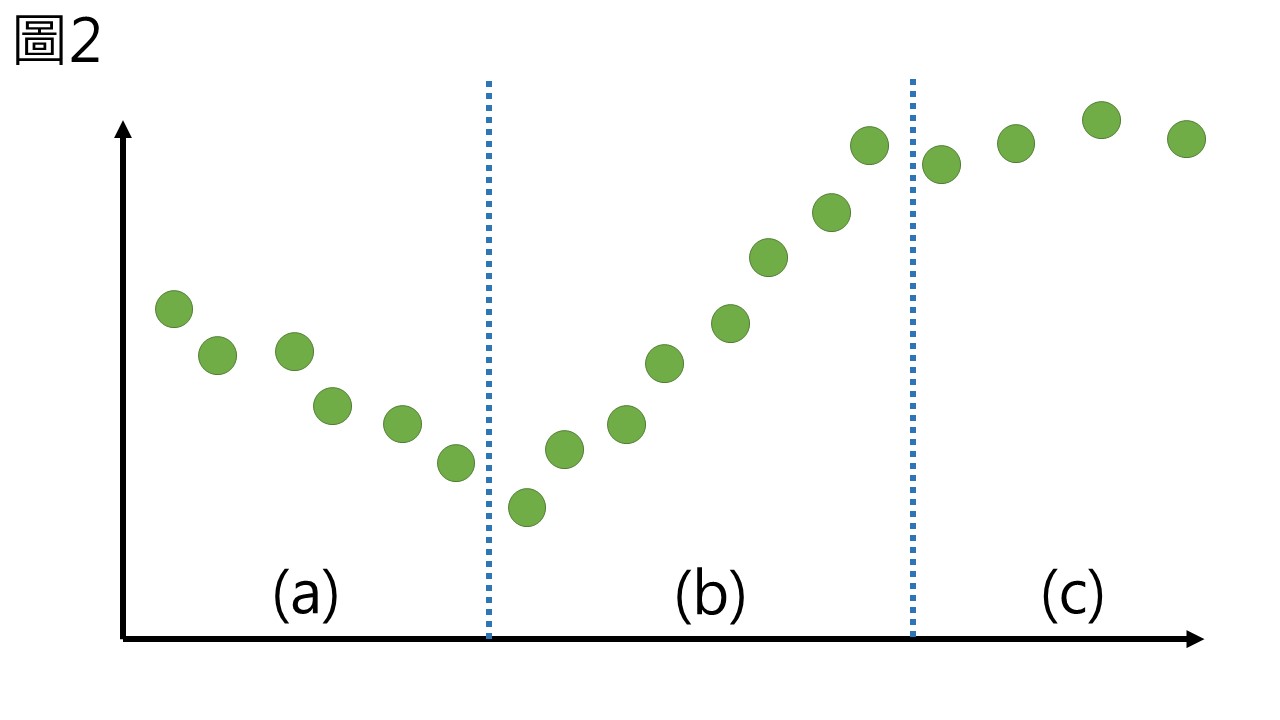
這樣的情況下,如果我們直接使用線性迴歸來計算,得出的結果不佳,但也不能憑直覺劃分區間,因此迴歸樹先使用決策樹來將資料分組,接著在各組內建立線性迴歸方程式,就可以針對性的建立多條迴歸直線 (圖3)。
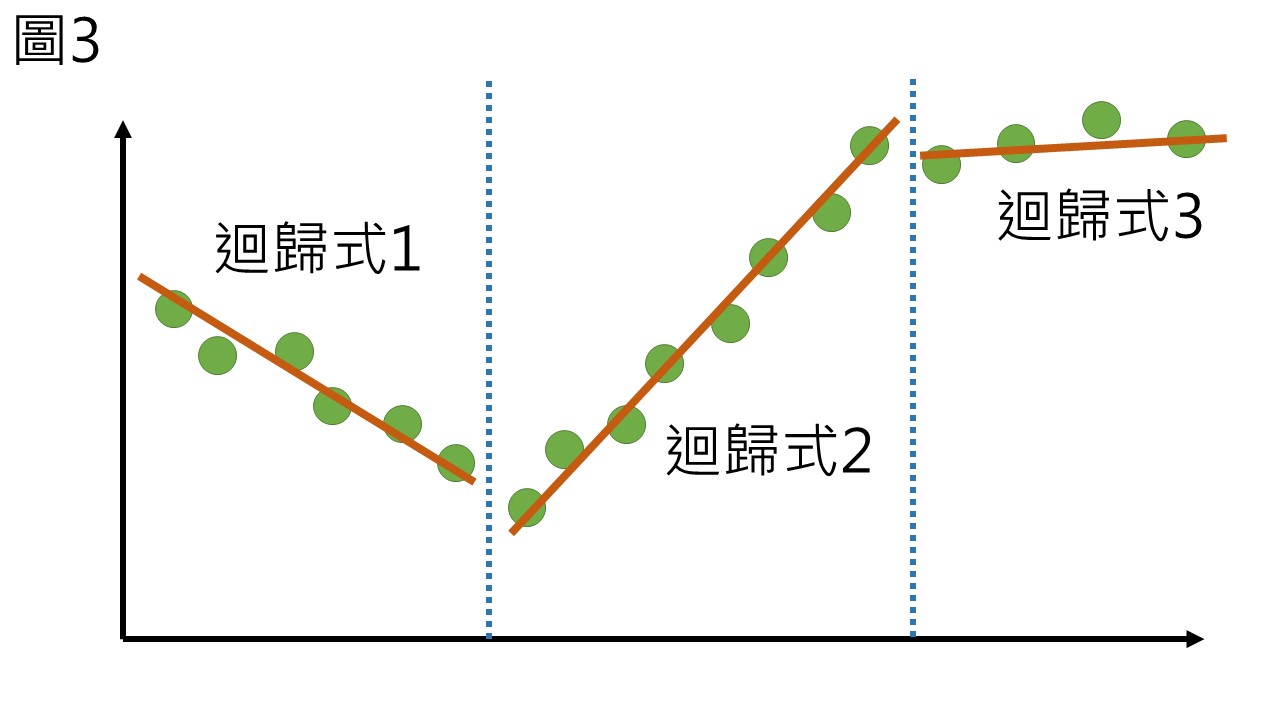
Cubist迴歸樹 (Cubist regression tree)
Cubist迴歸樹就是比M5迴歸樹又更加改良的演算法,原始碼是2011年由RuleQuest公司釋出,再由Max Kuhn等人編寫成R的套件,現在來分部講解Cubist迴歸樹的演算法。
Split criterion
Cubist迴歸樹的節點挑選基準跟M5是一樣的,一個節點可能產出P個子集合,假設原本的集合為S,而可以產出的子集合為S1, S2,…,SP,這個分割方式所降低的不純度如下
SD代表標準差,也就是將新子集合的標準差加權平均後看看有沒有低於原本的標準差,並選取標準差降低最多的一組作為節點。當第一個節點確立之後,將在節點建立迴歸式,而迴歸式的誤差 (error) 將取代SD代入上式,也就是新的節點選取是依靠能否降低迴歸誤差來區分。
一直持續選取節點,直到並無法再繼續區分 (一群內的點太少或是無法再降低不純度),每個節點的末端再進行線性迴歸,線性迴歸所使用的變數是他的上一個節點所使用的變數。
Rule-based
Cubist與M5最大的不同點是從M5的樹基底 (tree-based) 改變成了Cubist的規則基底 (rule-based),M5的樹基底包含一連串的if-then判斷,先判斷樣品點位於哪個區段,再決定他需要的迴歸方程式,也就是說每個樣品都需要經過一連串流水線式的判斷,最後才得到他的分區。
而規則基底則是將判斷式壓縮成扁平並立的規則,對於每個節點都建立一個規則,輸入後也都會得到一種答案,如圖4。
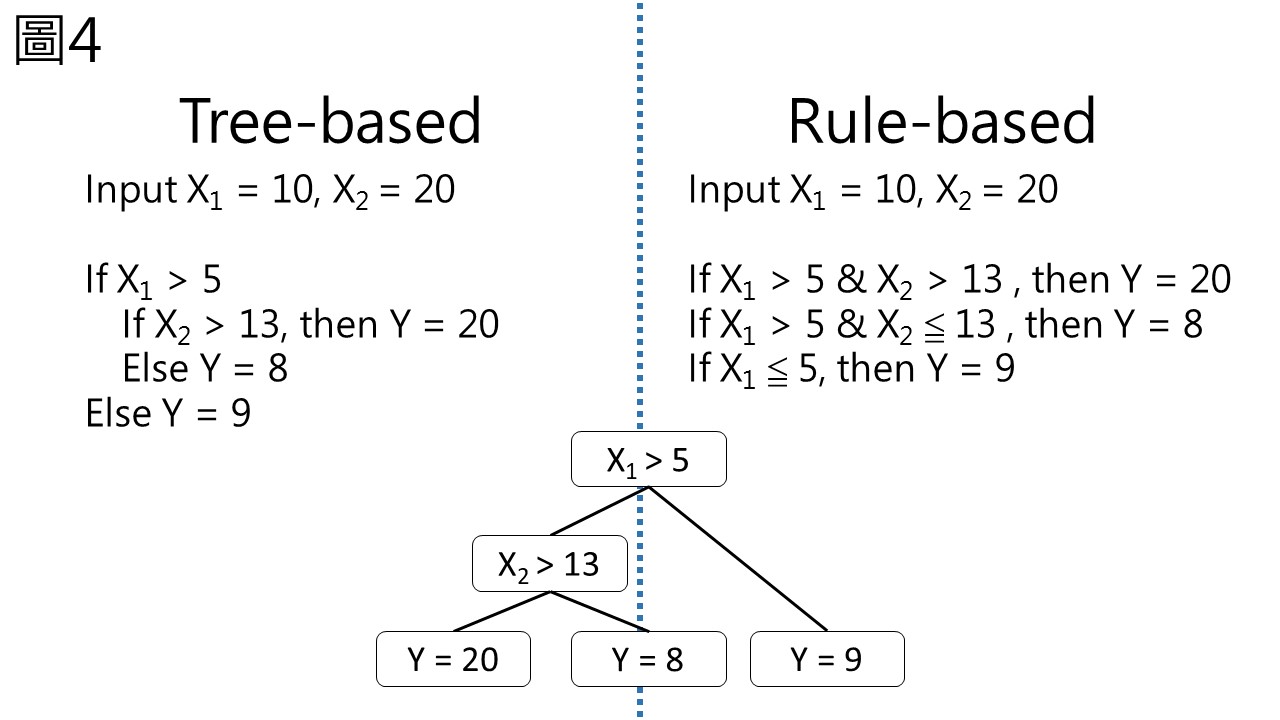
同樣的一棵樹,用樹基底的話要跑完所有判斷式才有一個結果,但規則基底則不同。在基底的最底端 (葉子) 將是一條迴歸直線。
Adjusted error rate
Cubist的修剪方法是衡量在末端的迴歸直線效果,當每個迴歸直線產出後,會將該直線所用到的所有變數一個一個剔除,並計算剔除後的調整錯誤率 (adjusted error rate):
n*是這個分類所使用的樣本數目,p是這個分類所使用的變數數目,若是剔除某個變數之後可以降低adjusted error rate,那麼就將該變數捨去,最多可以捨去所有變數,成為一條常數的線也行。
Committee
Cubist迴歸樹還使用一個名為委員會 (committee) 的參數,committee的做法是迭代式的生成一連串的規則基底 (與boosting有點類似)。一開始是使用上述的方法生成一棵樹並建立規則基底與各規則內的迴歸式,接著將此規則對部分資料進行驗證測試,測試結果若為過度適配或是效果不好,則進行修正並且建立下一個committee。
也就是說在產生第k個committee時,會使用到第k-1個committee的結果,使用方法如下:
若\(\widehat{y_i}_{(k-1)}\)太大,代表適配度不好,則下一個committee能夠在\(y_{i(k)}\)修正其影響,當全部committee都建立好之後,每個樣品的預測會經過全部committee的結果,再將所有committee的結果進行簡單的平均。
Neighbor–based adjustments
除此之外,Cubist迴歸樹可以用每個樣品周圍的鄰居來進行校正,當Cubist完成預測後,可以選擇使用Neighbor–based adjustments,並給定要選取的鄰居數量,此方法將找出樣品周圍的鄰居並且計算鄰居的平均。
另外在迴歸線之間的smoothing方法,Cubist也有其較為獨特的改良,由於較為細節就不在這裡敘述,有興趣的可以去讀Applied Predictive Modeling,裡面有關於Cubist的很多細節。
總體而言,Cubist迴歸樹改善了決策樹的缺點,並且可用於處理連續型變數,是一個可行且已經在實行的機器學習演算法,我將在碩士論文中使用這個演算法,到時有什麼心得或是發現會再更新。
參考資料
Rules Rules Rules! Cubist Regression Models (Max Kuhn製作的簡報,淺顯易懂)
Cubist Regresion Models (R的套件說明)
Visualizable and interpretable regression models with good prediction power
Comparison of Cubist models for soil organic carbon prediction via portable XRF measured data
Applied Predictive Modeling (非常詳盡的一本書,推薦必讀)